Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
(本文结尾有完整代码)
0.安装selenium库
pip install selenium1.下载对应浏览器的浏览器驱动
这里我用谷歌浏览器
Chrome 浏览器驱动下载地址
下载好直接解压到python的目录即可
2.导入库并设置无头浏览器(可选)
无头浏览器,也就是无界面化浏览器。
from time import sleep
from selenium import webdriver
# 无头浏览器设置
co = webdriver.ChromeOptions()
co.headless = True
browser = webdriver.Chrome(options=co)当co.headless = False时候有界面化
3.打开百度网址
url = 'https://www.baidu.com'
browser.get(url)因为我们的代码执行的速度比 百度服务器响应的速度快。
百度还没有来得及 返回搜索结果,我们就执行了如下代码
browser.implicitly_wait(3)这样如果找不到元素,每隔半秒钟再去界面上查看一次, 直到找到该元素, 或者过了3秒最大时长。
4.利用chrome的f12开查找搜索框和搜索按钮的id
也就是找到程序需要在哪里输入或点击的位置
首先按f12打开开发者工具,选择标签Elemes,再点击旁边的箭头
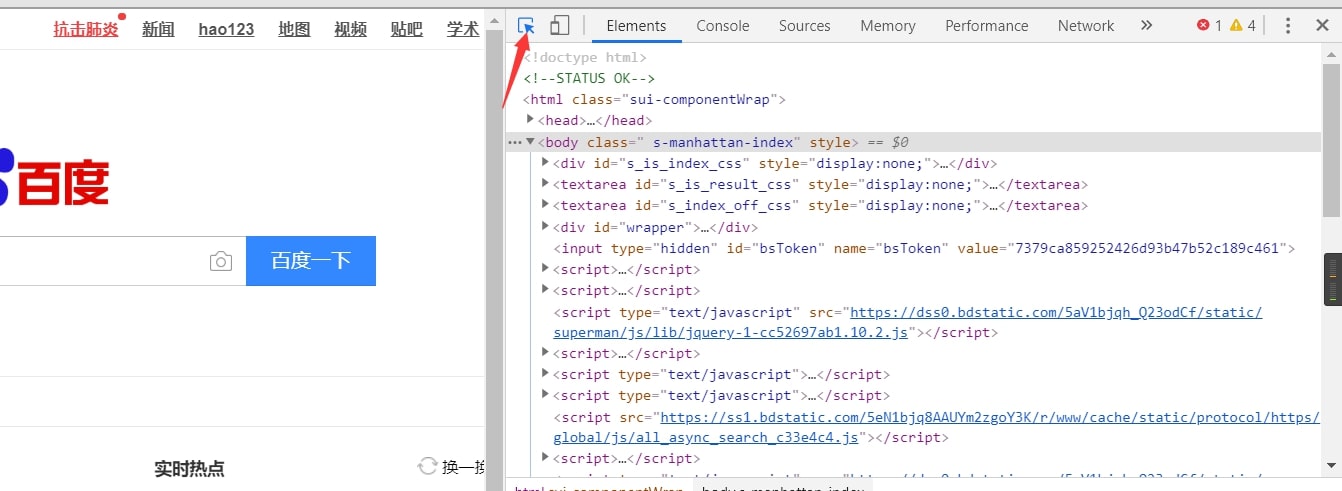
然后把鼠标放在输入框上在Elements上就会定位到该输入框的标签id,这个id在本网页中是唯一的
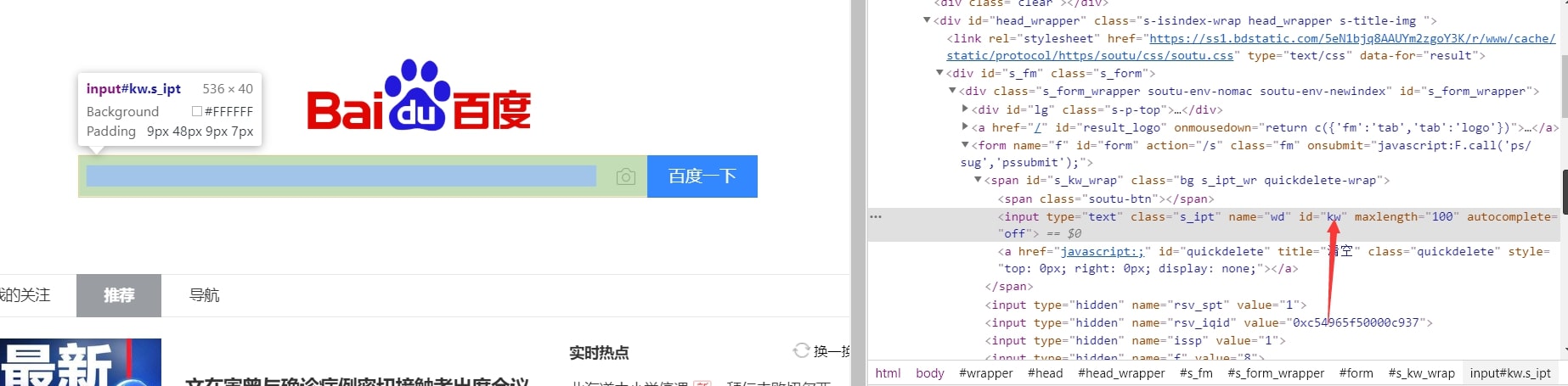
在把鼠标放在搜索框上同理得到搜索按钮元素的id

得到这连个id我们就可以继续写程序了
browser.find_element_by_id('kw').send_keys('kali搭建钓鱼wifi csdn') # 输入框
browser.find_element_by_id('su').click() # 点击搜索按钮==其中==
find_element_by_id()是寻找网页中元素的id
send_keys()方法可以在对应的元素中输入字符串
click()方法是点击该元素
5.查找搜索界面的元素id
如果你前面跟我一起做的没错的话,现在页面应该已经跳转到搜索结果了吧,
接下载和前面一样,找到每个结果元素的id
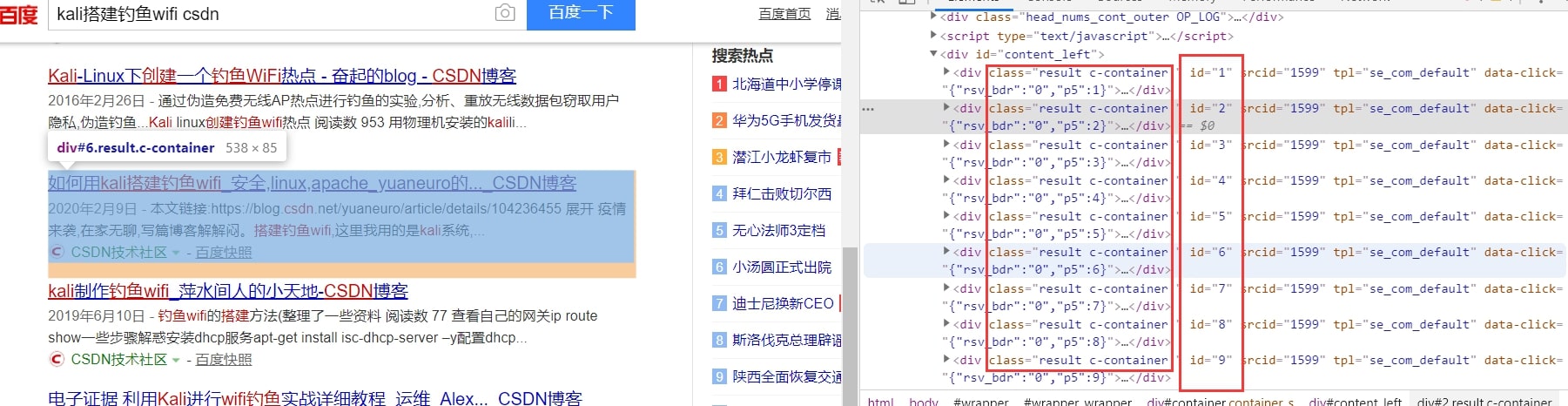
我们发现,每条结果的id是有规律的,id从1到10分别对应的10条搜索结果,并且他们同属于c-container类
所以我们直接查找所有c-container类
elements = browser.find_elements_by_class_name('c-container') # 查找到所有c-container类==注意==
这里用的是find_elements_by_class_name(),比前面查找id的多了一个s,该方法返回的是找到的符合条件的所有元素 (这里有3个元素), 放在一个列表中返回。
而如果我们使用 find_element_by_class_name (注意少了一个s) 方法, 就只会返回第一个元素。
6.使用for循环将结果输出
这里我们看到,搜索结果是放在a标签在的

所以我们用element.find_element_by_tag_name()查找到a标签在的文本,即搜索结果。
for element in elements:
span = element.find_element_by_tag_name('a')
print(span.text)7.爬取完毕,退出浏览器
sleep(2)
browser.quit()是不是很简单,只用了短短二十几行代码就搞定了!
完整代码
"""
用selenium百度搜索结果显示
"""
from time import sleep
from selenium import webdriver
# 无头浏览器设置
co = webdriver.ChromeOptions()
co.headless = True
browser = webdriver.Chrome(options=co)
browser.implicitly_wait(3)
url = 'https://www.baidu.com'
browser.get(url)
browser.find_element_by_id('kw').send_keys('kali搭建钓鱼wifi csdn') # 输入框
browser.find_element_by_id('su').click() # 点击搜索按钮
elements = browser.find_elements_by_class_name('c-container') # 查找到所有c-container类
for element in elements:
span = element.find_element_by_tag_name('a')
print(span.text)
# print(span.get_attribute('innerHTML'))
sleep(2)
browser.quit()