之前学的django的基础以及学的差不多了,以及理解它的流程并可以写出一个简单的页面了,只剩下第三方插件以及比较进阶的东西了,所以暂时先把django放一放,从这篇文章开始学习scrapy爬虫。虽然requests+selenium可以解决爬取90%的东西,但scrapy可以更高效更快的为我们爬取数据
scrapy爬虫流程
首先上一张图
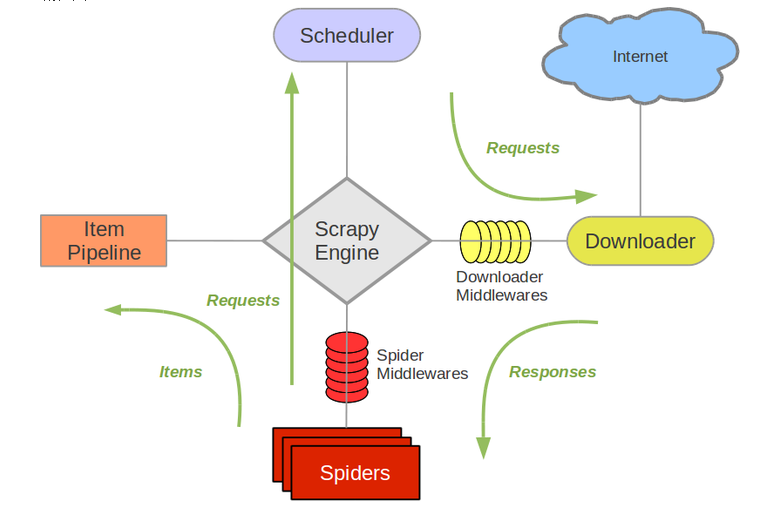
从图中我们可以看出scrapy分为4各部分,分别是
- Scheduler(调度程序)负责存放url
- Downloader(下载器) 负责发送请求
- Spiders(爬虫) 负责提取url和提取数据
- Item Pipeline(数据管道) 对提取的数据进行处理,存放数据队列
具体流程:
Scheduler先将requests对象交给Scrapy Engine,然后引擎再将requests对方发给Downloader- Downloader前有一个
Downloader Middlewares中间件,它可以将engin传来的requests对象或从Downloader传到引擎的requests对象进行一个过滤或处理,所以我们也可以自己写一个中间件对requests对象进行一些额外处理的。 - 接着将requests对象传给
Spiders,它提取到的url会一requests对象的方法传给Scheduler,并将提去的数据传递给Item Pipeline。同样我们也可以自定义Spider Middlewares中间件对经过spider的requests对象进行再处理。(但不会对爬到的数据进行处理,因为有专门处理的模块) Item Pipeline将Spiders爬取的数据进行处理和存放
注意:
Scheduler中存放的不是url地址,而是requests对象,其中包括url地址,headers等- 四个模块相互独立,他们之间的联系全靠引擎进行传递,进行解耦合,就算其中一个发生故障也不会影响其他模块,容错率会更高一些
- 我们需要自己写的代码就是
Spider和Item Pipeline,其他模块Scrapy已经帮我们实现
简单了解了一些scrapy,感觉还是selenium好用一点,所以暂时不学scrapy。
