之前学完了操作系统学习了作业的调度,对多任务有了一些了解。
但之前写爬虫是无奈不会多任务所以爬虫爬取速度较慢,所以今天来用python学习多任务,包括线程、进程、协程。
Thread创建线程 完成多任务
import threading
from time import sleep
def cat():
for i in range(5):
print('mmm%d' % i)
sleep(1)
def dog():
for i in range(5):
print('www%d' % i)
sleep(1.5)
if __name__ == '__main__':
t1 = threading.Thread(target=cat)
t2 = threading.Thread(target=dog)
t1.start()
t2.start()当我们执行start()的时候就会创建一个线程,此时会有两个线程:
- 主线程负责执行下面的东西,
- 子线程则会执行
target指向的函数,
当函数执行完后子线程自动结束,当全部代码执行完主线程结束,程序正常退出。
如果想让执行子线程的时候让主线程阻塞,则可以用join()即可
使用threading.enumerate()可以查看当前运行的所有线程
通过继承Thread类完成创建线程
import threading
from time import sleep
def dog():
for i in range(5):
print('www%d'%i)
sleep(1.5)
class Animals(threading.Thread):
def cat(self):
for i in range(5):
print('mmm%d'%i)
sleep(1)
def run(self):
self.cat()
if __name__ == '__main__':
t1 = Animals() # 创建这个类的实例对象
t2 = threading.Thread(target=dog)
t1.start()
t2.start()对于类的多线程创建时,需要将类继承threading.Thread,
然后在类中必须定义一个run函数,然后在run方法中写我们要执行多线程的代码,
然后创建这个类的实例对象,然后调用该类的start方法即可,
run方法执行完了,这个线程也就执行完了
线程池
线程池的作用就是不管你有多少个线程,每次运行的线程都是线程池规定的个数,比如线程池规定5个,而现在创建了10个线程,那么只有5个会执行,某一个执行完了之后,又会自动进来一个。
- 创建线程池是通过
concurrent.futures函数库中的ThreadPoolExecutor类来实现的
import threading
from concurrent.futures import ThreadPoolExecutor
lock = Lock()
def target():
for i in range(5):
with lock:
print(threading.get_ident(), i)
with ThreadPoolExecutor(5) as t:
for i in range(100):
t.submit(target)多线程共享全局变量
- 在一个进程内所有线程共享全局变量,很方便多个线程间共享数据
- 缺点:线程是对全局变量随意修改可能造成多线程之间对全局变量的混乱(即线程非安全)
共享全局变量会产生资源竞争
例如:
import threading
from time import sleep
a = 0
def test1(num):
global a
for i in range(num):
a+=1
print('test1', a)
def test2(num):
global a
for i in range(num):
a+=1
print('test2', a)
if __name__ == '__main__':
t1 = threading.Thread(target=test1, args=(10000000,))
t2 = threading.Thread(target=test2, args=(10000000,))
t1.start()
t2.start()
sleep(3)
print(a)按理说最后答应的结果是20000000,但实际运行结果却是:
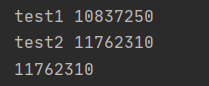
- 这是为什么呢?
这就是资源竞争,因为当他计算+1的时候会有很多步骤,而系统进行调度的时候采用时间片轮转,有可能前一个+1运算还没结束就会轮转到下一个线程中,所以造成对共享变量的重复覆盖
解决方法
让每次执行的代码具有原子性(即不可分割),即用线程同步来解决
同步就是协同步调,按预定的先后次序进行运行
所以我们可以用互斥锁来解决:
- 某个线程要更改共享数据时,现将其锁定,此时资源的状态为“锁定”,其它线程不能更改,直到该线程释放资源,将资源状态变成“未锁定”,其它线程才能再次锁定该资源。互斥锁保证了每次只有一个进程进行写入操作,从而保证了多线程情况下数据的正确性
在threading中定义了Lock类,可以方便处理锁定:
# 创建锁
mutex = threading.Lock()
# 上锁
mutex.acquire()
# 释放
mutex.release()为了防止acquire后忘记release,建议使用上下文管理器:
lock = threading.Lock()
with lock:
...
...如果这个锁之前是没有上锁的,那么acquire()就不会被阻塞
如果在调用acquire()对这个锁上锁之前它已经被其他线程上了锁,那么此时acquire会被堵塞,直到哪个锁被释放为止
死锁
但是当有两个及以上的锁是,可能会出现死锁的情况,及两个或多个线程同时占有对方需要的资源时,谁也没法获取自己想要的资源就会造成死锁
死锁的避免
- 添加超时时间
- 银行家算法
